Data for AI is expensive, and too many models are built that never get used by the people they’re designed to help. You can solve both problems with the same approach. Before you invest in the data needed to train an accurate model, begin with one-on-one engagement with the people you serve, and collect the data in the process. Here’s a method for how to progress through that.
This follows on to a conversation that I had recently with Derek Russell and Ali Mazaheri on their show, Simply TECH LIVE. The topic that we covered was Empathy – The Most Effective Journey to Innovations in AI. And you can check out the show here:

Derek honored me with an invite to their show after a story that I shared with him about a lean startup-inspired approach to building AI, based on my work with the MirrorHR team. Below is how this can apply to you and the story behind it.
The common approach is an anti-pattern
Many teams begin with the pattern of collecting the data and training a model prior to really engaging with the people they will serve—often called the customers or users. They get a theory in mind and then overcommit by getting the data to build the model. The common problem happens where you are building the wrong thing.
When I describe this to engineers, I tell them:
It is a premature optimization to build the solution before you have deeply spoken with people about the problems that you will solve for them.
The worst inefficiency is to build the perfect solution, on time and on budget, that nobody needs or wants.
Instead, I recommend an approach that matches to an empathy-building solution.
Data are people first
In Data Are People First, you can read how to create a culture of empathy-informed business and product creation. It is important to build empathy early and use this to ensure that you’re on the right track.
When working with machine learning models, you often need large quantities of data to train a model (DNN). And you need to ensure that it is tuned to your target audience. It is difficult to tune this and ensure that you get it right. Also, it is expensive to acquire that data.
In deep or very specific domains, it’s incredibly hard to source natural quantities of data. Instead, source the data through your empathy research.
Here’s how the MirrorHR team did this.
MirrorHR’s product development story
In my day job, I have the privilege of incubating an incredible project with a noble mission. MirrorHR, aka Epilepsy Research Kit for Kids, helps families of children with epilepsy by reducing the number and severity of their children’s seizures.
Their approach uses AI in two ways. This includes real-time monitoring of biological markers like heart rate for patterns and they pair this information with qualitative diary entries from the families and caregivers.
This pairing of quantitative and qualitative information helps the families collaborate with their healthcare team to gain insights, identify triggers, and consequently deter the seizures.
This is very specific information that is needed and thus requires a customer ML model.
Most importantly, these are families with very strong, emotional conditions surrounding them and their work. They don’t have the time to deal with something that may or may not help them. They interact with any kind of “solution” which in moments of extreme stress, and the information that they share is highly personal.
It is very important for the team to have extremely high touch engagement with these families as they build something to meet their razor-sharp needs.
It turns out, as is often the case in a well-articulated focus statement, this challenge also informs the answer. Here is where the pattern begins to emerge.
The team can offer a high touch experience, while developing empathy, and collecting data and ground truth needed to train their model by beginning with people on their team receiving and recording the diary entries manually.
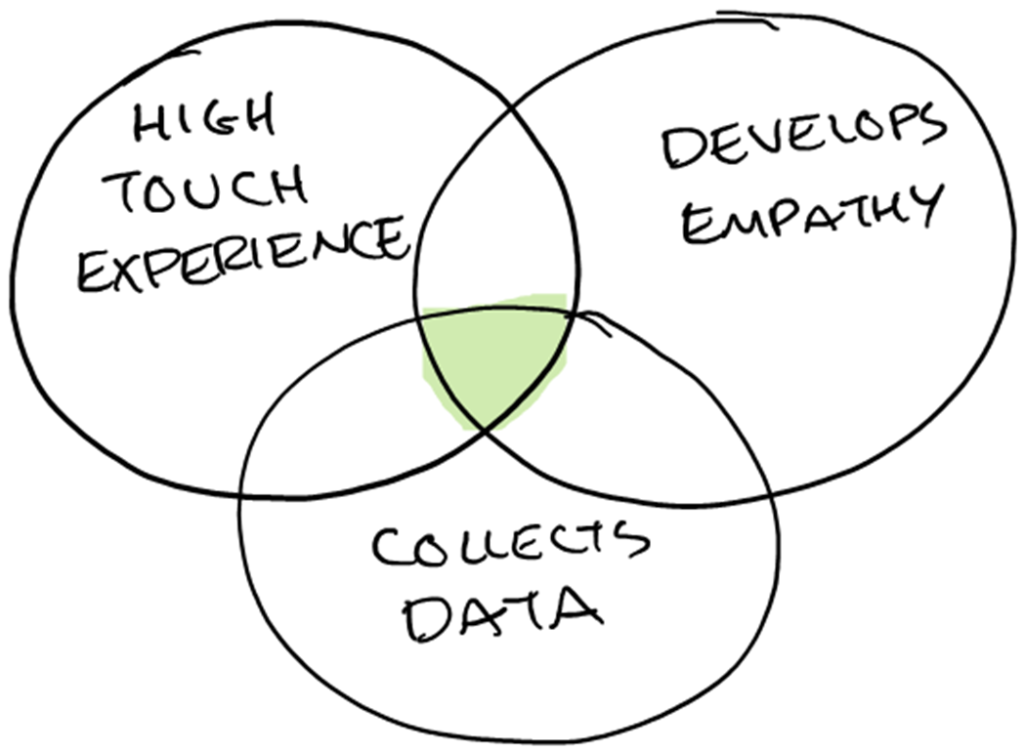
The members of the team are on the calls to provide high touch and receive empathy while logging and tagging the information to build up the corpus of data and ground truth* for later training the model.
* Ground truth is the information obtained on the ground by people recording what is actually occurring in the data so that the model can be trained on this.
Beginning with this, you can fit this into a larger progression.
The progress from human intelligence to full AI
In this way the continuum goes from fully leveraging human intelligence to fully leveraging artificial intelligence.
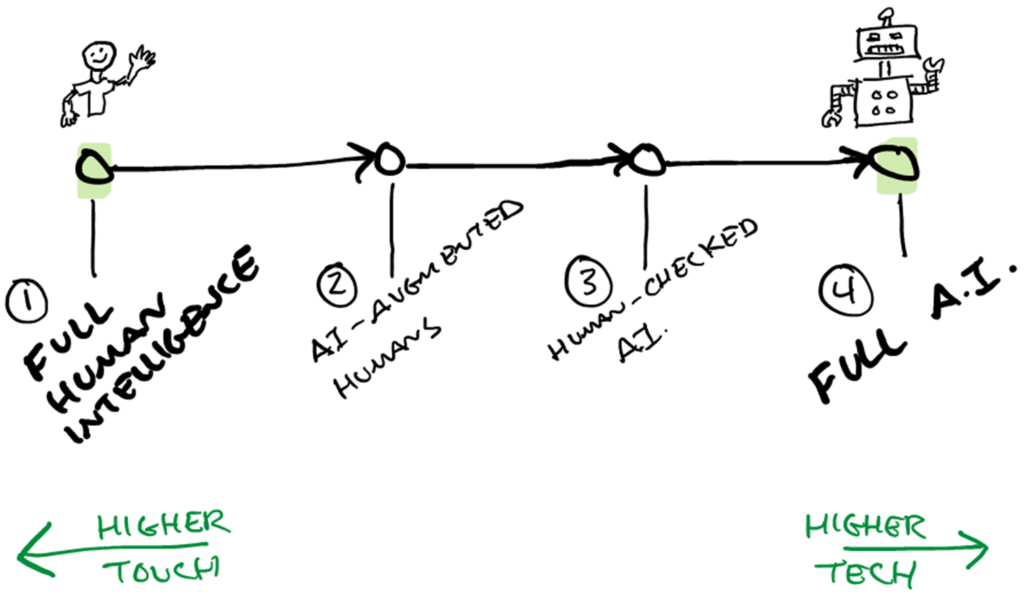
Phase 1: Full Human Intelligence – During this phase, the teams’ earliest members have the conversation, logging and tagging the data, working with as few people who use the product as possible.
Phase 2: AI-augmented (AI-assisted) Human Intelligence – When ready and needed, begin to replace some of the human intelligence and manual labor with AI systems to expedite the process and start onboarding more people to help. This phase is gradually entered as the pressure from people you are serving gets higher and higher.
Phase 3: Human-augmented (human-checked) AI – Over time, this shifts to AI being the primary means of doing the work with human’s there to correct the AI’s mistakes.
Phase 4: Full Artificial Intelligence (AI) – Eventually, you get to an AI solution that is well-tuned and doesn’t require human intervention, except when the people using it flag the rare error for the team to correct.
This progression improves scalability, with the human touch going away, the user experience diminished in the later phases. However, it unlocks new possibilities.
Create better experiences through AI on the edge
My friend and colleague Jacopo Mangiavacchi, the Tech Lead for the MirrorHR team, pointed out to me that Phase 4 assumes a more traditional AI implementation, but as you remove the humans and the need to roundtrip data by the humans, you can move to new architectures.
The current one collects data on the cloud and automates on the cloud, which has drawbacks to latency, privacy, and user experience. However, more sophisticated approaches can lead to better user experiences.
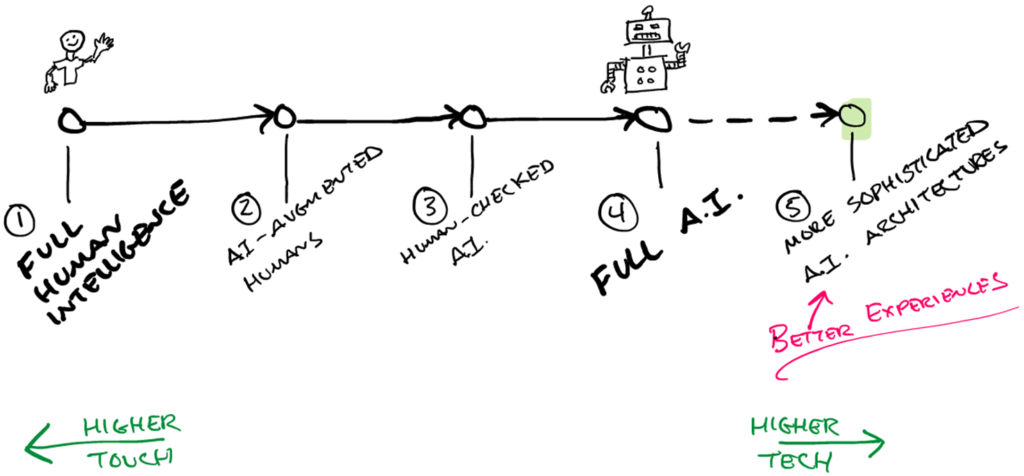
Phase 5: More Sophisticated A.I. Architectures – Although the tech and scalability have been improving from Phases 1 through 5, the reduction of the human element can lead to a less tuned experience even as the model is better. As an experimental phase beyond today’s traditional AI implementations, new approaches can emerge that explore Computing on the Edge. This can reduce the roundtrip and storage of highly private user data on the servers. If can even reduce roundtripping.
Further, it helps to know a little bit about the state of AI models today. Instead of a single monolithic model, AI is often composed as a system of models. Some of these are building blocks like transcription services, translation services, Azure’s Cognitive Services, etc.
More sophisticated architectures can decompose these into the constitutes parts and never send private information from the local devices.
It’s already common that in these AI systems, some key elements are implemented as hardware, instead of software, that runs locally and never needs to roundtrip to the server at all, increasing security, privacy, and compute speed.
All these approaches are using technology to improve the user experience, and many of the models will reflect deep engineering team understanding of the people using the tech. And this can best be achieved through need foundations in technology.
It’s also of note that although this is listed as phase 5, some elements of it can begin in phase 3. However, until the system is fully AI-automated, there will always need to be some parts of it seen by humans through client-to-server transmission of data.
Also important to integrate ML into the experience instead of offline.
Another advantage of this is that customized, reinforcement learning style AI will benefit from AI on the Edge. Typically, these are less complex models, and tuning them on the Edge will lead to more personalized AI solutions that are tuned to the individual people using that device.
These are the frontiers of where AI can go. In the meanwhile, let’s return to the roots of the Phase 1 approach to begin with all Human AI.
Inspired by startups
This approach is inspired by many who have come before us in the startup world. Such as Paul Graham’s exhortation to founders to Do Things That Don’t Scale. The story told of AirBnB in here, and also relayed by Brian Chesky and Reid Hoffman in the Handcrafted episode of the Masters of Scale podcast were an inspiration to this team.
Conclusion
So, if you’re working in AI, begin by doing the things that don’t scale, to earn your right to do the things that do scale. That’s how you build on a solid foundation of keen insight and empathy for the people you serve. This will help all of the people involved: the people on your team, the people who invest in you, and the people you serve.
If you found this valuable
Please consider subscribing, sharing, and commenting.
I liked the connection to building concierge services and then automating the humans away–really nice application of that context in the space of ML. One thing that would be interesting is exploring when to choose between actually using AI vs simply scaling humans with more basic heuristics. It seems like a strength of this approach is that it will uncover the cases where you *don’t* need AI at all.
Asking questions are really fastidious thing if you are not understanding anything completely, however this article gives nice understanding yet. Dulcia Guido Bartlet
I don’t usually comment but I gotta admit appreciate it for the post on this amazing one : D.
واقعاً سایت شفاف و تمیز، ممنون برای این پست
magnificent points altogether, you simply won a emblem new reader.